
This is Part 0 of a four-part report — see links to Part 1. Part 2. Part 3, and a folder with more materials.
Abstract
In the next few decades we may develop AI that can automate ~all cognitive tasks and dramatically transform the world. By contrast, today the capabilities and impact of AI are much more limited. Once we have AI that could readily automate 20% of cognitive tasks (weighted by 2020 economic value), how much longer until it can automate 100%? This is what I refer to as the question of AI takeoff speeds; this report develops a compute-centric framework for answering it.
First, I estimate how much more “effective compute” – a measure that combines compute with the quality of AI algorithms – is needed to train AI that could readily perform 100% of tasks compared to AI that could just perform 20% of tasks; my best-guess is 4 orders of magnitude more (i.e. 10,000X as much). Then, using a computational semi-endogenous growth model, I simulate how long it will take for the effective compute used in the largest training run to increase by this amount: the model’s median prediction is just 3 years. The simulation models the effect of both rising human investments and increasing AI automation on AI R&D progress.
How to read this report
The right approach depends on your technical background:
- Non-technical readers should first watch this video presentation (slides), then read this blog post, and then play around with the Full Takeoff Model here.
- Moderately technical readers should first read the short summary, then play around with the Full Takeoff Model here, and then read the long summary.
- If you have a background in growth economics, or are particularly mathsy, you might want to read this concise mathematical description of the Full Takeoff Model.
I do not recommend reading the full report top to bottom. Instead, treat its sections as providing longer discussions of the important modelling assumptions and parameter values of the model.
This section lists particular sections of the full report that I think would be useful to read after the long summary.
1. Short summary
In the next few decades we may develop AGI that could readily[1]The phrase “readily” here indicates that i) it would be profitable for organisations to do the engineering and workflow adjustments necessary for AI to perform the task in practice, and ii) they could make these adjustments within 1 year if they made this one of their priorities. perform ~all cognitive tasks as well as a human professional. If we can run enough AGIs, they could ~fully automate cognitive labour and dramatically transform the world.
By contrast, today the capabilities and impact of AI are much more limited. How sudden might this transformation be? More precisely: once AI is capable enough, and we can run enough copies, that AI can readily automate 20% of cognitive tasks (weighted by 2020 economic value), how much longer until AI can readily automate 100%?[2]Milestones of the form “AI could readily automate x% of tasks” require both that AI is capable enough to perform the tasks and that we can run enough copies for AI to replace every human doing those tasks. By contrast, the definition of AGI as “AI that could readily perform 100% of tasks” … Continue reading This is what I refer to as the question of AI takeoff speeds.[3]By contrast, in Superintelligence takeoff speed is defined as the time from human-level AI to superintelligence. I discuss this, but it is not my focus because I think the bigger crux in takeoff speeds relates to the time from sub-human but hugely impactful AI to human-level AI (more).
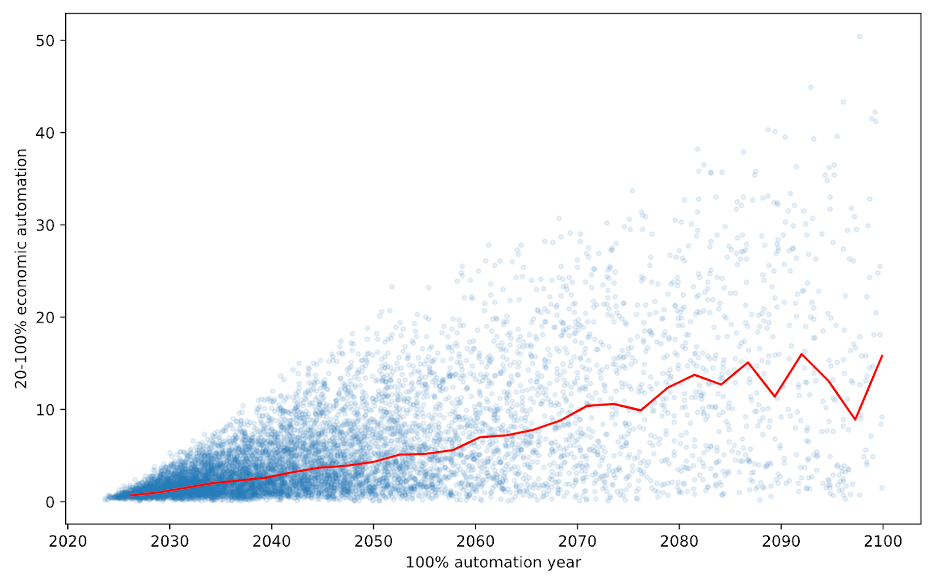
X-axis: first year that AI could readily automate 100% of cognitive tasks in the global economy.
Y-axis: how many years previously could AI readily automate only 20% of these tasks?
This report develops a framework to estimate takeoff speeds, extending the biological anchors framework (Bio Anchors) for predicting when we’ll develop AGI (AI that could readily perform ~100% of cognitive tasks)[4]The explicit forecasting target of Bio Anchors is “transformative AI”, but the framework can be used to forecast AGI.. It also has implications for AGI timelines.
I use a compute-centric framework in which:
- Some amount of compute would have been sufficient to train AGI using ideas and algorithms from 2020.[5]More precisely, if experts in 2020 were given ~2-5 years to experiment with the new quantity of compute and design a training run, they could train AGI (more). The exact amount is highly uncertain and very large compared to today’s biggest training runs.
- Software progress, by which I mean improvements in ideas and algorithms for training AI systems, merely decreases the compute required to train AGI. Or, equivalently, software progress increases the amount of “effective compute” we have to train AGI.
- Effective compute = software * physical compute.
- So one FLOP training AIs with 2025 software may be worth ten FLOP with 2020 software.
- All forms of algorithmic progress are represented as increasing the quantity of effective compute per unit of physical compute.
In this framework, AGI is developed by improving and scaling up approaches within the current ML paradigm, not by discovering new algorithmic paradigms.
Within this compute-centric framework, I first estimate the ‘capabilities distance’ we need to traverse during takeoff. Second, I calculate the ‘speed’ at which we will acquire those capabilities by simulating a macroeconomic model of software R&D, hardware R&D, and increasing spending on AI training runs. Then takeoff time ~= distance / average speed.[6]This is a slight oversimplification. Takeoff time as defined here is time from AI that could readily perform 20% of tasks to AI that could perform 100%. Whereas the metric I ultimately report is AI could readily automate 20% to 100%. The latter accounts for whether we have enough compute to run … Continue reading
More precisely, by ‘distance’ I mean: How much more effective compute do you need to train AI that can readily perform ~all cognitive tasks (AGI) compared to weaker AI that can only readily perform 20%[7]Why 20%? The choice of startpoint is fairly arbitrary. 5% would be too low, as it could be driven by a few one-off wins for AI like “automating driving”; 50% would be too high as by then AI may already be having ~transformative impact. of these tasks (weighted by 2020 economic value)? I call this the effective FLOP gap you need to cross during AI takeoff. Its size is very uncertain, but we can make guesses weakly informed by evidence from ML and biology.
My best guess is that the effective FLOP gap is ~4 orders of magnitude (OOMs): we’ll need 104 times as much effective compute to train AGI as to train AI that can readily perform 20% of cognitive tasks. But anything from ~1 OOM to ~8 OOMs seems plausible.
By our “speed” crossing the effective FLOP gap I mean: how quickly will we increase the effective compute used in the largest training run?
We can cross the gap by increasing three quantities:
- The quality of AI software, i.e. algorithms for training AI. If the level of software doubles, we get twice as much effective compute for each FLOP.
- The quality of AI hardware, measured as FLOP/$. Improved hardware allows us to buy more FLOP with a fixed budget.
- $ spend on FLOP in the largest training runs.
These three quantities multiply together to give the effective compute in the largest training run:
Effective compute in the largest training run = software * FLOP/$ * $ on FLOP.
This implies we can calculate our speed crossing the effective FLOP gap as:
g(effective compute in the largest training run) = g(software) + g(FLOP/$) + g($ on FLOP).
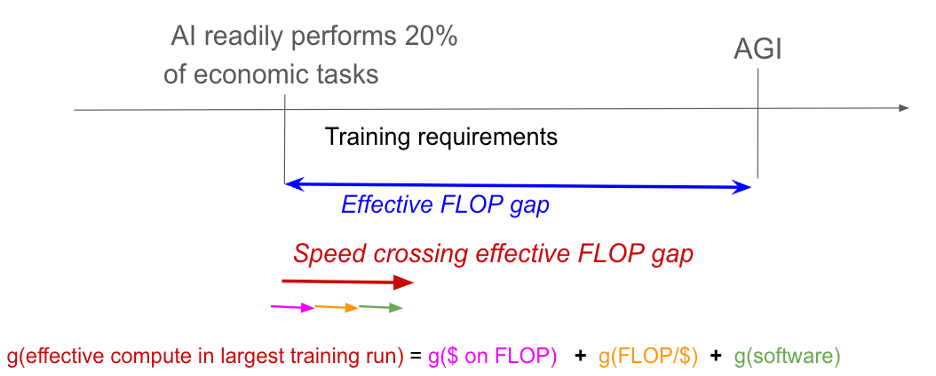
As we cross the effective FLOP gap, AI automates more tasks and so AI R&D progress accelerates. Link to diagram.
I use a computational model, the Full Takeoff Model, to calculate the evolution of software, FLOP/$ and {$ on FLOP in the largest training run}. The Full Takeoff Model is designed to capture the most important effects from:
- Rising human investments in software R&D, hardware R&D and AI training runs.
- I use semi-endogenous growth models to predict how R&D spending will translate into software and hardware progress.
- Increasing AI automation of software R&D, hardware R&D, and the broader economy.
- I use CES task-based models to predict how AI automation affects software R&D progress, hardware R&D progress, and GDP.
- The model implies that software, hardware and GDP grow increasingly quickly as we cross the effective FLOP gap and AI automates more tasks.
- I assume it is somewhat easier for AI to automate cognitive tasks in {software and hardware R&D} than in the broader economy. This makes takeoff faster.
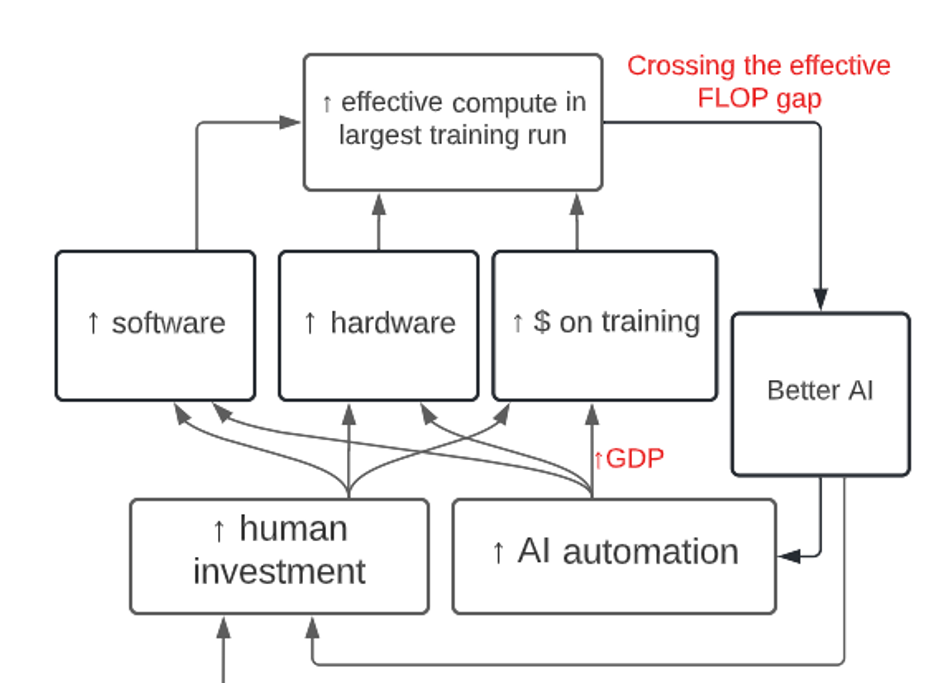
The Full Takeoff Model makes assumptions about the compute needed to train AGI using 2020 algorithms, the size of the effective FLOP gap, the pace at which human investments rise, the diminishing returns to hardware and software R&D, bottlenecks from tasks that AI cannot perform, and more. It calculates trajectories for software, hardware, $ on training, effective compute in the largest training run, and GDP.
In the playground you can enter your preferred parameter values and study the results.
($ on FLOP in largest training run ~= $ on FLOP globally * fraction of global FLOP on training)
1.1 Monte Carlo analysis
We perform a Monte Carlo analysis to get a distribution over takeoff speed given our uncertainty about these parameters:
| MC results
Percentile |
Takeoff speed[8]Conditional on 100% automation by 2100. Years from “AI could readily automate 20% of cognitive tasks” to “AI could readily automate 100% of cognitive tasks”[9]Reminder: milestones of the form “AI could readily automate x% of tasks” require both that AI is capable enough to perform the tasks and that we can run enough copies for AI to replace every human doing those tasks. By contrast, the definition of AGI as “AI that could readily perform 100% of … Continue reading |
|
| Tasks in the general economy. | Tasks in software and hardware R&D.[10]Why is takeoff slower for AI R&D tasks? The Monte Carlo puts weight on AI R&D being significantly easier to automate than the general economy. If so then, by the time AI can readily automate 20% of tasks in the general economy, it will have already automated most tasks in AI R&D and … Continue reading | |
| 1% | 0.3 | 0.9 |
| 10% | 0.8 | 1.6 |
| 20% | 1.2 | 2.2 |
| 50% | 2.9 | 4.3 |
| 80% | 7.6 | 9.6 |
| 90% | 12.5 | 14.6 |
| 99% | 28 | 30.7 |
There is a strong relationship between the difficulty of developing AGI and takeoff speed. If AGI is easier to develop then (in expectation):
- The effective FLOP gap is smaller, because it is bounded from above by AGI training requirements. [11]If AGI could be trained with X OOMs more effective compute than today’s largest training run, the effective FLOP gap must be <X OOMs.
- Our average speed crossing it is higher:
- One way to quickly cross the effective FLOP gap is to quickly increase the fraction of the world’s computer chips used on the largest training run.
- If AI is easy to develop, this fraction will still be small when we start crossing the effective FLOP gap. So there’s more room to grow the fraction as we cross the gap.
- If in addition the effective FLOP gap is small (point 1), we could cross most of the gap merely by increasing the fraction. I.e. we could cross the gap very quickly.
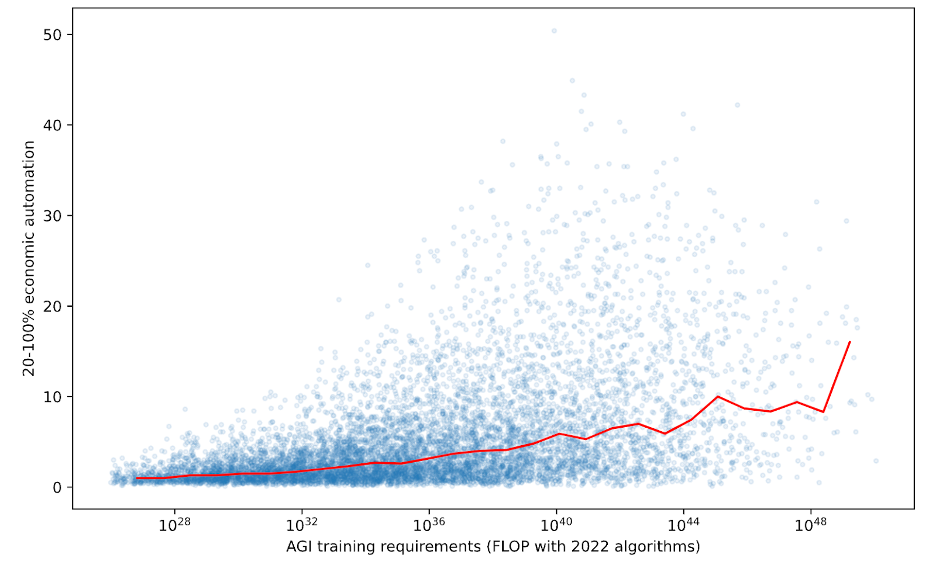
To get to my personal all-things-considered bottom line, I eye-ball adjusted the Monte Carlo results for incorporate limitations of the model, especially i) ignoring types of discontinuous progress around AGI that can’t be represented by a narrow effective FLOP gap and ii) not modelling various lags to training and deploying advanced AI.
My personal probabilities are still massively in flux, but my current best guesses are:
| Beliefs of the author
Percentile |
Takeoff speed Years from “AI could readily automate 20% of cognitive tasks” to “AI could readily automate 100% of cognitive tasks”.[12]Reminder: milestones of the form “AI could readily automate x% of tasks” require both that AI is capable enough to perform the tasks and that we can run enough copies for AI to replace every human doing those tasks. By contrast, the definition of AGI as “AI that could readily perform 100% of … Continue reading |
|
| Tasks in the general economy. | Tasks in software and hardware R&D. | |
| 3% | 0.1 | 0.3 |
| 10% | 0.3 | 1 |
| 20% | 0.8 | 2 |
| 50% | 3 | 5 |
| 80% | 10 | 12 |
| 90% | 20 | 25 |
1.2 How much time from AGI to superintelligence?
This has not been my main focus, but the framework has implications for this question. My best guess is that we go from AGI (AI that can perform ~100% of cognitive tasks as well as a human professional) to superintelligence (AI that very significantly surpasses humans at ~100% of cognitive tasks) in less than a year. The main reason is that AGI will allow us to >10X our software R&D efforts, and software (in the “algorithmic efficiency” sense defined above: effective FLOP per actual FLOP) is already doubling roughly once per year.
1.3 Implications for AI timelines
Compared to Bio Anchors, this framework predicts larger maximum $ spend on the largest training for AGI, includes additional speed-ups from AI automation, and models the possibility we could leverage enormous amounts of runtime compute to get full automation sooner. As a result, its median predicted AGI year is 10 years earlier than Bio Anchors (2043 vs 2053), despite using the same distribution over AGI training requirements.
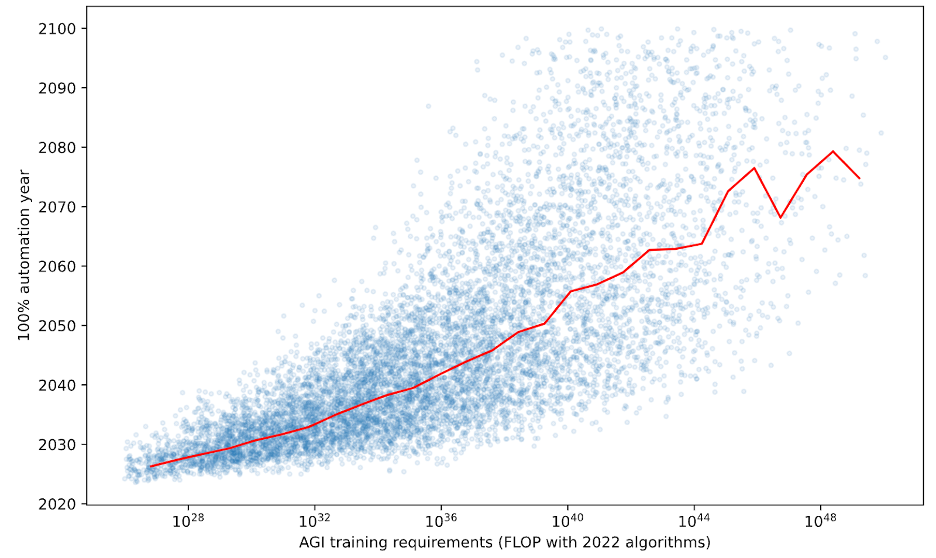
1.4 Notable assumptions and limitations of the framework
- Compute-centric framework that assumes that some amount of compute would be sufficient to train AGI in 2020, and that algorithmic progress merely reduces that amount.
- Models software and compute as inputs to AI development, but not data/environments.
- Assumes that AI capabilities improve continuously with software research effort (research into AI algorithms). More.
- Ignores lags between developing and deploying AIs, and ignores other delays. More.
- I mostly focus on the transition to AGI rather than the aftermath of AGI, as this is where I think the origin of fast takeoff is most likely to be. More.
- Cannot directly make predictions about many strategically-important AI milestones.
- It can predict “AI can readily add $10tr/year to GDP”, “AI can readily automate 30% of R&D”, “GDP is growing at 30%/year”, or “AI cognitive output exceeds that of 10 billion humans”.
- It cannot predict “AI has situational awareness”, “AI is super-human at persuasion/deception”, or “AI kills us all if it’s not aligned”. Though these are plausibly correlated with things the framework can predict.
I recommend playing around with the Full Takeoff Model before reading the summary.
I recommend that readers familiar with economic growth theory now read a concise mathematical description of the full economic model.
Acknowledgements
- To Carl Shulman especially for introducing many of the core ideas.
- To Jaime Sevilla, Eduardo Infante Roldán, and others at Epoch for coding up the Full Takeoff Model, creating the playground and many helpful suggestions.
- To Dan Kokotajlo, Holden Karnofsky, Paul Christiano, Ajeya Cotra, Luke Muehlhauser, Lukas Finnveden, Leopold Aschenbrenner, Joe Carlsmith, Peter Favaloro, Tamay Besiroglu, Owen Cotton-Barratt, Ege Erdil, Eliezer Yudkowsky, Nate Soares, Basil Halpern, Marius Hobbhahn, Ali Merali, Alyssa Vance, Eric Neyman, Lukas Gloor, Anton Korinek, Jakub Growiec, Eli Lifland, Charlotte Siegman, Ben Levinstein, David Schneider-Joseph and Jacob Trefethen for helpful feedback.
2. Long summary
2.1 What is takeoff speed?
Roughly speaking, I focus on the amount of calendar time between “AI is capable enough to have massive economic impact” and “AI is that is completely transformative”.
I’m not aware of a very principled way to specify the startpoint and endpoint here.
One option is economic growth rates, e.g. years from GDP growing at 5%/year to 30%/year. This is easily measurable, but has the downside that AI capabilities might grow explosively but have little, or very delayed, impact on GDP due to various bottlenecks.
AGI can be defined as AI that can perform ~100% of cognitive tasks as well as a human professional,[13]This could be one generally capable AI, or many narrow AIs working together. I think the takeoff model I ultimately use sits better with the latter interpretation. and a second option to extend that definition to less capable AI. In particular, quantify AI capabilities via the % of cognitive[14]By “cognitive task” I mean “any part of the workflow that could in principle be done remotely or is done by the human brain”. So it includes ~all knowledge work but also many parts of jobs where you have to be physically present. E.g. for a plumber it would include “processing the visual … Continue reading tasks AI can readily perform, where each task is weighted by its economic value in 2020. (The phrase “readily” here indicates that i) it would be profitable for organisations to do the engineering and workflow adjustments necessary for AI to perform the task in practice and ii) they could make these adjustments within 1 year if they made it one of their priorities.) This second option also dovetails nicely with economic models of automation, but it has a few weaknesses.[15]First, it will be hard to measure in practice what % of cognitive tasks AI can perform (more). Second, there are not literally a fixed set of tasks in the economy; new tasks are introduced over time and AI will contribute to this (more, more). Thirdly, at what cost can AI perform these tasks? The … Continue reading
A third option is the % of cognitive tasks AI can readily automate. This is like the second option but comes with the additional requirement that we can run enough copies of the AI(s) to actually replace the humans currently performing the tasks. This is more relevant to the collective cognitive capacity of AI systems. Today, valuations of AI market size are $10-100b,[16]E.g. here, here, here, here. I don’t know how reliable these estimates are, or even their methodologies. suggesting that AI can readily automate <1% of cognitive tasks.[17]AI’s impact on GDP may be greater than its market size, but it would have to have to be adding ~$0.5tr/year to GDP to have automated 1% of cognitive tasks.
The full sensitivity analysis includes a variety of ways of quantifying takeoff speed, but I currently focus on years from “AI could readily automate 20%[18]Why 20%? The choice of startpoint is fairly arbitrary. 5% would be too low, as it could be driven by a few one-off wins for AI like “automating driving”; 50% would be too high as by then AI is already having ~transformative impacts. of cognitive tasks” to “AI that could readily automate 100% of cognitive tasks”.
- The startpoint corresponds to AI that could readily increase world GDP by ~$10tr/year,[19]World GDP is ~$100tr, about half of which is paid to human labour. If AI automates 20% of that work, that’s worth ~$10tr/year. [This is a bit high, as many tasks have a component of physical labour (though all have some cognitive component). On the other hand, AI will probably produce more … Continue reading assuming AI was deployed wherever it was profitable.[20]More precisely, deployed anywhere where i) it would be profitable for organisations to do the engineering and workflow adjustments necessary for AI to perform the task in practice and ii) they could make these adjustments within 1 year if they made this one of their priorities.
- Standard Baumol effects will diminish the fraction of GDP paid to the automated tasks after they are automated, but this is still the effect on total GDP.
The endpoint corresponds to AI that could collectively replace all human cognitive output. I believe that by this point we very likely have AI that could permanently disempower all of humanity if it wanted to.
2.2 Calculating takeoff speed
2.2.1 What’s driving the results on a high level?
My process for estimating takeoff speed is as follows:
- First estimate the effective FLOP gap.
- Roughly speaking, this is the “difficulty gap” from AI that can readily perform 20% of cognitive tasks to AGI. How much harder is the latter to develop than the former?
- Within our compute-centric framework, we translate “How much harder?” to “How much more effective compute is required during training?”.
- More precisely, the effective FLOP gap means: How much more effective compute do you need to train AGI compared to AI that can only readily perform ~20% of cognitive tasks (weighted by 2020 economic value)?
- Result: the effective FLOP gap is ~1 – 8 OOMs, best guess ~4 OOMs.
- Use a toy model to estimate how quickly we’d cross the effective FLOP gap from human investments alone, ignoring the effects of AI automation.
- This can be roughly interpreted as “How fast would takeoff be if no one ever actually deployed the AIs in the real world, and just used them for demos?”
- Result: we initially increase the effective compute in the largest training run by ~0.7 OOMs/year, then this falls to ~0.4 OOMs/year as we can no longer increase the fraction of the world’s AI chips on the largest training run. In my best-guess scenario, with a gap of 4 OOMs, I get an average speed of ~0.5 OOMs/year and so takeoff takes ~8 years.
- At this point we’re assuming that soon after we get AI that can readily perform x% of tasks, we can run enough copies that AI could readily automate x% of tasks. This turns out to be an OK simplification.
- Simulate the Full Takeoff Model (FTM) to calculate how quickly we will cross the effective FLOP gap in the best-guess scenario. The FTM:
- Models the effects of human investment more carefully, including some additional bottlenecks and complications that the toy model ignored.
- Result: this slows takeoff in the best-guess scenario to ~12 years.
- Uses a standard model of automation from growth economics to predict the effect of partial AI automation on software progress, hardware progress, and GDP (and thus $ spend on training runs).
- As the effective compute used in the largest training run increases, AI automates more and more tasks.
- Result: this speeds up takeoff in the best guess scenario to ~5 years.
- The FTM keeps track of how many compute we have for running AIs, so it can calculate the desired “AI could readily automate x% of tasks” metric.
- Models the effects of human investment more carefully, including some additional bottlenecks and complications that the toy model ignored.
- Run a Monte Carlo simulation to get a probability distribution over takeoff speed.
- The incompatibility between low AGI training requirements and large FLOP gaps lowers the median sampled effective FLOP gap to ~3.3 OOMs. This speeds up median takeoff to ~4 years.
- The possibility that it’s easier for AI to automate {hardware and software R&D} than the general economy reduces the median takeoff to ~3 years.
- Takeoff speed in the [10th, 50th, 90th] percentiles of the Monte Carlo are ~[0.8, 3, 11] years.
- The <1 year takeoff is mostly driven by:
- Small effective FLOP gap + large scope for increasing the fraction of chips used for the largest training run → you can quickly cross the gap by increasing spending on the largest training run.
- The possibility of significant AI R&D automation by the time we start crossing the gap.
- The <1 year takeoff is mostly driven by:
To summarize:
| Estimate | Takeoff speed |
| Toy model without AI automation | 8 years = 4 OOMs / 0.5 OOMs per year |
| Full Takeoff Model with best-guess inputs | 5 years |
| Median result from the Monte Carlo | 3 years |
The next three sections discuss the size of the effective FLOP gap, the toy model that excludes AI automation, and the Full Takeoff Model’s treatment of AI automation.
2.2.2 The effective FLOP gap is ~1 – 8 OOMs, best guess ~4 OOMs
How much more effective compute do you need to train AGI than to train AI that can readily perform ~20% of cognitive tasks (weighted by 2020 economic value)?
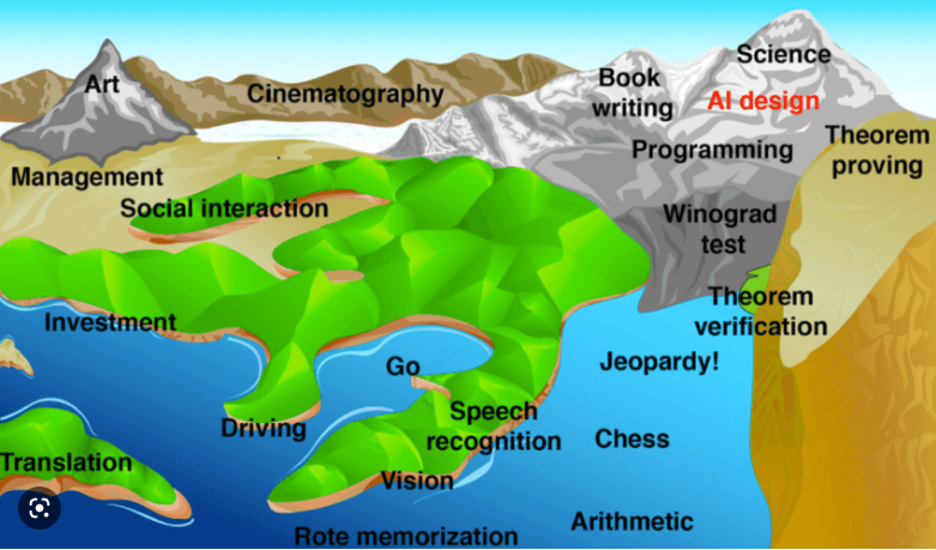
Currently AI can only readily perform a small fraction of cognitive tasks – the areas of the map that are underwater. Over time the AI capabilities improve and the tide rises. Eventually, AI can readily perform all cognitive tasks: we’ve crossed the effective FLOP gap and everything is under water.
The size of the effective FLOP gap is very uncertain, but evidence from biology and ML can weakly inform the choice. Here’s a brief summary of some key pieces of evidence.
- AGI training requirements place an upper bound on the effective FLOP gap.
- E.g. if AGI can be trained with 1e36 FLOP with 2020 algorithms (my median) and we’ve already done a 3e24 FLOP training run, the gap must be <7.5 OOMs.
- Limitations of SOTA AI tighten this bound.
- I think a 300X scale-up of today’s SOTA AI (1e27 effective FLOP) wouldn’t be sufficient to readily perform 20% of cognitive tasks, in which case the effective FLOP gap must be <9 OOMs.
- How AI capabilities vary with training FLOP: suggests ~5 OOMs
- GPT-3 had a ~300X bigger training run than GPT-2; you can play around with both to get a feel for their capabilities. I guess you might need two equally big improvements to cross the effective FLOP gap, which implies it’s ~5 OOMs.
- GPT-N looks like it will solve some LM benchmarks ~4 OOMs earlier than others (see diagrams in link); I’d guess the effective FLOP gap will be bigger than this as economic tasks are much more varied along many dimensions.
- How human + animal capabilities vary with brain size: suggests ~2 OOMs
- Data suggest a 10% bigger brain (in terms of FLOP/s) grants ~5 extra IQ points. Extrapolating heroically, a 10X bigger brain grants ~120 IQ points, which seems sufficient to cross the effective FLOP gap.
- Anchoring to model size, a 10X bigger model might require 100X more training FLOP, suggesting a gap of ~2 OOM.
- Anchoring to lifetime learning compute, a 10X bigger brain requires 10X more lifetime learning FLOP. So you might see the same improvement in ML by increasing training FLOP by 10X → gap of ~1 OOM.
- You could get smaller gaps by using smaller IQ point gaps.
- You can make similar arguments via chimp/human comparisons.
- Importantly, this approach ignores the fact AI may have strong comparative advantages over humans on some tasks but not others, allowing very “limited” AIs to automate many tasks.
- Data suggest a 10% bigger brain (in terms of FLOP/s) grants ~5 extra IQ points. Extrapolating heroically, a 10X bigger brain grants ~120 IQ points, which seems sufficient to cross the effective FLOP gap.
- Practical difficulties with partially automating jobs: suggests a smaller effective FLOP gap.
- For AI to be able to readily perform 20% of cognitive tasks, it must be able to do so without too much additional engineering work or rearranging of workflows.[21]Reminder: if AI can “readily” perform a task then i) it would be profitable for organisations to do the engineering and workflow adjustments necessary for AI to perform the task in practice, and ii) they could make these adjustments within 1 year if they made this one of their priorities.
- If there are significant practical difficulties in partially automating jobs,[22]E.g. Brynjolfsson (2018) finds that “most occupations include at least some [automatable by machine learning] tasks; (iii) few occupations are fully automatable using ML; and (iv) realizing the potential of ML usually requires redesign of job task content. then the capabilities for non-trivial partial automation may only be a little lower than those for full automation.
- We can incorporate this by using a smaller effective FLOP gap than we otherwise would have.
- Horizon length.
- If “short horizon”[23]This concept is from Bio Anchors. Short horizons means that the model only needs to “think” for a few seconds for each data point; long horizons means the model needs to “think” for months for each data point and so training requires much more compute. training can perform 20% of cognitive tasks but performing all cognitive tasks requires “long horizon” training, the effective FLOP gap will be >5 OOMs.[24]There are ~5 OOMs between a “10 second” horizon length and a “1 month” horizon length.
| Evidence | Effective FLOP gap estimate |
| AGI training requirements + Limitations on SOTA AI | <~9 OOMs |
| How AI capabilities vary with training FLOP | ~5 OOMs |
| How human + animal capabilities vary with brain size | ~2 OOMs |
| Practical difficulties with partially automating jobs | Shorter gap |
| Horizon length | >5 OOMs |
| Overall | ~4 OOMs (~1 to 8 OOMs) |
All in all, my best-guess is that the effective FLOP gap is ~4 OOMs, with values from ~1 to ~8 OOMs possible. Lower than ~2 OOMs feels out-of-whack with how SOTA AI abilities scale with training FLOP and with the plausibility of AI having strong comparative advantages on certain tasks; much higher than ~5 OOMs feels in tension with how IQ scales with brain size in humans and chimps.
More on evidence about the size of the FLOP gap.
2.2.3 Speed crossing the effective FLOP gap from human investment, ignoring AI automation
Recall, we cross the effective FLOP gap by increasing the effective compute used in the largest training run, which can be calculated as
Effective compute in the largest training run = software * FLOP/$ * $ on FLOP.
This implies we can calculate our speed crossing the effective FLOP gap as:
g(effective compute in the largest training run) = g(software) + g(FLOP/$) + g($ on FLOP).
This section estimates how quickly each of these three components will grow due to rising human investments as we approach AGI.
Background – “waking up” to advanced AI’s economic potential
I believe pre-AGI systems have the potential to increase world GDP by $10s of trillions per year. By contrast, AI software and hardware investments are currently in the $10s billions. So I expect investments in AI to grow more rapidly once relevant actors “wake up” to the economic and strategic potential of AI.[25]This could be either AI organisations reinvesting revenues from AI products, or impressive demos attracting external investment. I don’t model either in detail and instead just try to ballpark the overall rate of investment growth.
Let’s look at the effect of human investment on each component in turn.
More $ spent on FLOP for the largest training run
I split this into two sub-components:
$ on FLOP for the largest training run = $ on FLOP globally * fraction of global FLOP on the largest training run
I guess that $ on FLOP globally will double every ~3 years, based on evidence about recent semiconductor revenue growth, the time to build a fab, and the expansion of munitions production at wartime.[26]This, like FLOP production as we approach AGI, is an example of “growth of a specific industry’s output when there is suddenly very large demand”. More.
I estimate that there’s currently room to increase the fraction of global FLOP on the largest training run by ~3 – 4 OOMs, but that this will decrease to ~1 – 2 OOMs by 2030. After “wake up”, I guess the fraction will increase by ~3X per year (growth rate of 72%) until it hits a cap. This quickly moves us through part of the effective FLOP gap, and then stops having an effect. More.
I forecast faster growth here than Bio Anchors, shortening timelines. Bio Anchors forecasts $ on FLOP for the largest training run to only grow at 3% after reaching ~$200b, whereas I expect it to continue to double every ~3 years (growth rate of ~22%) after “wake up” until it caps out at ~1% of world GDP (though in simulation, we typically get AGI before training runs are this big).
More FLOP/$ from better quality hardware
Bio Anchors directly extrapolates past trends in FLOP/$, predicting a 2.5 year doubling time. By contrast, I fit a semi endogenous growth model to historical data about how hardware R&D spending translates into more FLOP/$, predict future R&D spending, and then calculate future FLOP/$.
The fitted model suggests that each doubling of cumulative hardware R&D spending drives ~5 doublings of FLOP/$. So if cumulative spending grows at x%, FLOP/$ is predicted to grow at 5x%.[27]This assumes the growth rates are instantaneous growth rates, defined as e^gt. All the growth rates I report are instantaneous.
Recently the growth rate of cumulative spending has only been ~5%, and annual hardware R&D spending is <$100b. This suggests there’s plenty of room for spending to grow after “wake up”.
I guess that annual R&D spending will grow at ~17% (~4 year doubling) after “wake up”. This is based on eye-balling historical growth of hardware R&D, growth of R&D in other areas, and growth in US defense and space R&D after WW2.[28]This, like hardware R&D as we approach AGI, is an example of “growth of a specific industry’s R&D when there is suddenly very large demand”.
If cumulative R&D spending were growing at 17%, I’d predict that FLOP/$ would grow 17*5= 85% (~0.8 year doubling). But it turns out that if annual spending suddenly switches from 5% to 17% growth, then growth of cumulative spending rises gradually from 5% to 17%, only exceeding 10% after ~8 years.[29] This sheet illustrates the dynamic. So my current forecast is that, after “wake up”, FLOP/$ initially doubles every ~3 years but grows increasingly quickly over time.[30]The Full Takeoff Model caps total hardware R&D spending at 1% of global GDP.
This forecast feels a little slow. It’s plausible that annual R&D spending has a quick one-off increase of >2X before growing more slowly, and this would imply faster growth of FLOP/$ with less delay. On the other hand, I’m not sure the R&D sector could productively absorb that much money, and I’m forecasting the growth of quality adjusted R&D inputs.
More on the effects of human investment on FLOP/$.
Better software
My process for software is the same as for hardware: I fit a semi endogenous growth model to historical data about how software R&D spending translates into better software, predict future software R&D spending, and then calculate future software.
There’s massive uncertainty in the historical data about the rate of software improvement. Most measurements of software progress in specific domains suggest the quality of algorithms doubles[31]The report operationalises “a doubling of software” to mean: your algorithms now use physical FLOP twice as efficiently. So doubling software has exactly the same effect as doubling your quantity of physical FLOP. every ~1-2 years; I follow Bio Anchors’ in making the conservative assumption that progress for AGI training algorithms is slower, with a doubling time of only 2.5 years. A more aggressive assumption here would reduce AGI timelines by 2-5 years and speed up takeoff.
Combined with a shaky estimate of the growth of software R&D spending, the fitted model implies that each doubling of cumulative software R&D spending drives ~1.25 doublings of software.
I forecast that cumulative spending will grow at ~25% after “wake up”, implying that software will grow at 25*1.25 = 31%, a ~2.2 year software doubling time.
More on the effects of human investment on software.
Total time to cross the effective FLOP gap from human investment
So, combining the above, I calculate the growth of the the largest training run after “wake up” as follows:

What might this imply about takeoff speed? If there’s a 4 OOM effective FLOP gap, and you can cross 1 OOM by increasing “the fraction” (of global FLOP used on the largest training run), then it will take you ~8 years to cross overall.[32]Time = distance / speed = 3 OOMs to cross without the fraction / [~0.4 OOMs/year] = ~8 years.
Note, if the effective FLOP gap was only 2 OOMs, you could cross it in just 2-3 years.[33]1 OOM to cross with the fraction * 3 years per OOM = 3 years. So increasing “the fraction” allows you to cross short FLOP gaps especially quickly.
If you’re confused about how the different quantities discussed here combine together to give an estimate of takeoff speeds, I recommend looking at this toy model.
The parameters discussed in this section (the growth rates of human investment and the returns to hardware and software R&D) play important roles in the Full Takeoff Model.
2.2.4 Speed crossing the effective FLOP gap, including effects from AI automation
The results of this section ultimately come from simulating the Full Takeoff Model, a economic growth model that combines the effect of human investment and AI automation to estimate how the effective FLOP on the largest training run changes over time.
The main thing the FTM adds to the analysis above is modelling AI automation of software R&D, hardware R&D, and GDP. So let’s start by examining that part of the FTM.
AI automation increases our average speed crossing the effective FLOP gap by ~2.5X
AI automation increases GDP and the amount of hardware and software R&D progress made each year. This causes the effective compute on the largest training run to grow increasingly quickly as we cross the effective FLOP gap.
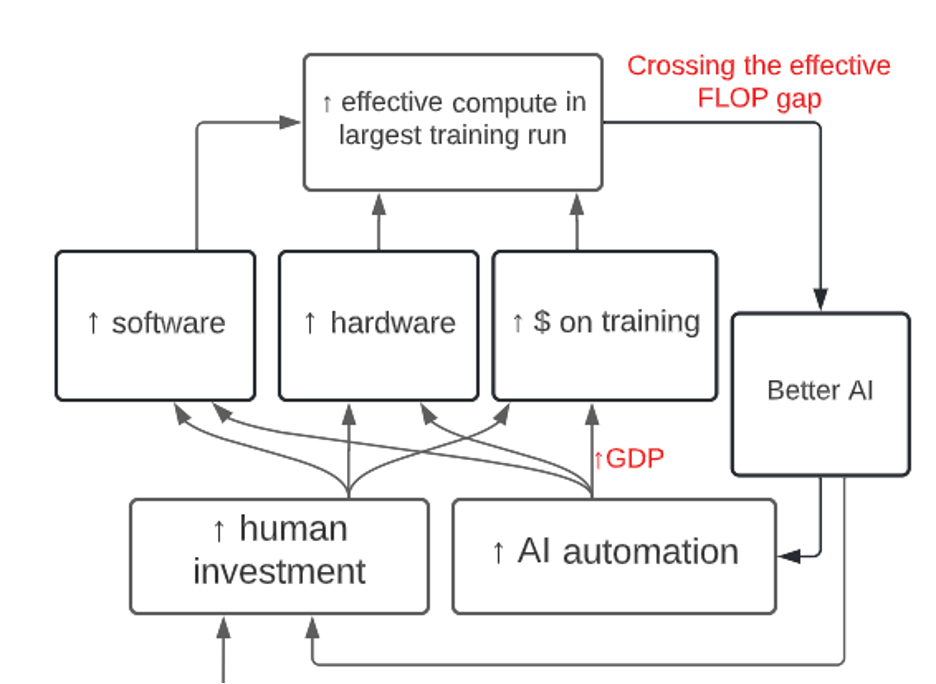
To estimate the effect of continuously increasing AI automation I adapt a task-based CES model from the economic automation literature.[34]The resultant model of automation is perhaps most similar to Hanson (2000). Here’s a very simplified toy version of what my model says about how AI automation affects GDP. (Later I’ll introduce various complications.)
- At first, AIs perform <1% of economic tasks, reflecting current annual AI revenues being <1% of global GDP. The other tasks are performed by humans, so GDP is ~proportional to the number of humans. (There’s no capital in this toy example; it is in the FTM and I discuss it below.)
- Over time, the effective compute in the largest training run increases. As a result, AIs automate an increasing fraction of economic tasks.[35]Automating a task requires both that AI can perform it and that there’s enough runtime compute to automate the task in practice (i.e. enough compute to cheaply replace the humans currently doing the task). It turns out that runtime compute is rarely a bottleneck to automation.
- This increases GDP.
- How much by?
- Let’s say AIs automate 50% of tasks. This boosts GDP in two ways.
- Firstly, humans can focus on the remaining 50% of tasks, and AIs can match the per-task output of humans, increasing the output per task by 2X. This boosts GDP by 2X.[36]Here I’m assuming that AI output-per-task at least keeps up with human output per task. I can assume this because it’s a condition for AI automating the tasks in the first place.[37]If AI had automated x% of tasks, the boost here would equal 1/(1-x%).
- Secondly, AIs soon have more output-per-task than humans, because there are many more AIs than humans. This increases GDP even further.
- How much further depends on the extent to which GDP is bottlenecked by the unautomated human tasks.[38]In the growth model, the strength of this bottleneck depends on the substitutability between different tasks: how much can more AI labour on task 1 make up for limited human labour on task 2?
- I consider some weakly-relevant empirical evidence about the strength of these bottlenecks.
- My best-guess for the bottleneck implies that GDP could rise a further 4X in this example, if you had unlimited AIs performing their 50% of tasks.
- Exactly what the boost is depends on how many AIs you run to do the automated tasks. After “wake up”, I think actors will be willing to spend a lot of $ running AIs that can accelerate hardware and software progress, so I expect this number to be large.[39]The Full Takeoff Model assumes that the percentage of global compute used to run AIs doing software rises quickly to a cap of ~20% after “wake up”.
- So AI automating 50% of tasks increases GDP by ~2X – 8X.
- By analogous logic, automating 20% of tasks boosts GDP by ~1.2X – 2X; automating 75% of tasks boosts GDP by ~4X – 60X.[40]Here’s the formula. If AI automates x% of tasks, the minimum effect is 1/(1-x%); the maximum effect is 1/(1-x%)^(1 + 1/-rho), where rho controls the strength of the bottleneck. My best guess is rho=-0.5, so the maximum effect is 1/(1-x%)^3. 1/(1-0.2) = 1.25, 1.25^3=1.95; 1/(1-0.75) = 4, 4^3=64.
- How do we decide how much automation has happened? The FTM has a mapping from {effective compute in the largest training run} to {% of cognitive tasks that AI can perform}.
- In the best-guess scenario the mapping is such that:
- 1e36 effective FLOP[41]I.e. an amount of effective compute equivalent to using 1e36 FLOP with 2020 algorithms. → AI can perform 100% of cognitive tasks
- 1e32 effective FLOP → AI can perform 20% of cognitive tasks
- This matches the best-guess effective FLOP gap of 4 OOMs.
- In the best-guess scenario the mapping is such that:
- Eventually, AI performs 100% of tasks (i.e. we train AGI) and GDP is proportional to the number of AIs we can run (which is proportional to $ on FLOP running AIs * FLOP/$ * software).
The logic described here for AI automation’s effect on GDP is the same as for its effect on R&D input. Simply replace “GDP” with “R&D work done per year” – after all GDP is simply the value of goods and services produced per year. So AI automating 50% of R&D tasks would boost annual R&D progress by >2X. (Caveat in fn.)[42]This is the short term boost to annual R&D progress you’d get if you instantaneously automated 50% of R&D tasks. Longer term, your faster R&D progress would increase diminishing returns and so your rate of annual progress would slow over time. The short term boost calculation is … Continue reading
The Full Takeoff Model (FTM) complicates the above simple model by assuming that a fixed fraction of tasks are performed by capital: machines and equipment. Neither AIs nor humans can perform these tasks. This means that GDP (/R&D work done per year) is never proportional to the number of AIs. In fact, even with unlimited AGIs, GDP (/R&D work done per year) cannot exceed a certain limit due to being “bottlenecked” by the amount of capital we have. I consider a few weakly-relevant sources of evidence about the strength of this bottleneck. My wild guess for these bottlenecks is that, if AI automated all cognitive tasks and we had unlimited AGIs but no additional capital, then GDP would increase by ~6X while hardware R&D progress would increase by ~100X.
For software R&D, the FTM assumes that the role of capital is instead played by physical compute for doing computational experiments. A limited amount of physical compute has the potential to bottleneck software progress. More.
The FTM has slightly lower training requirements for automating software and hardware R&D, compared with the general economy. This speeds up takeoff somewhat, because by the time AI can readily automate 20% of economic tasks it may have already automated (e.g.) 40% of R&D tasks, significantly speeding up AI progress.
What’s the overall effect of AI automation on the speed crossing the effective FLOP gap? This is hard to reason about analytically, but our simulations suggest AI automation reduces the time from “AI that can readily automate 20% of tasks” to “AI that can readily automate 100% of tasks” by ~2.5X.[43]These results are strikingly similar to those of a simple toy model. In the toy model, crossing the effective FLOP gap corresponds to travelling along the x-axis from 1 to 0. Without AI automation your speed equals 1 unit/second throughout; you cross the entire effective FLOP gap in one second and … Continue reading
If you’re confused about how AI automation affects our previous calculation of takeoff speeds, I recommend looking at the version of the toy model that incorporates AI automation.
How the FTM works
The Full Takeoff Model (FTM) combines the key dynamics discussed above:
- Each timestep it calculates the effective compute in the largest training run (= software * FLOP/$ * $ on FLOP in the largest training run), then uses this to determine how many tasks AI can automate. Then it calculates how software, FLOP/$, and $ on FLOP in the largest training run increase during that timestep.
- Software and FLOP/$:
- These increase due to software R&D and hardware R&D.
- For the tasks not yet performed by AI, inputs of labour and capital grow as discussed in the section ignoring AI automation:
- The human labour and physical capital invested in hardware R&D grows at ~17% after “wake up”,[44]One caveat here: once GDP starts growing more quickly, physical capital starts growing more quickly too. This causes capital inputs to hardware R&D grow somewhat more quickly than 17%. and at their current rate (~4%) before.
- The human labour invested in software R&D grows at 25% after “wake up”, and at their current rate (~20%) before.
- “Wake up” is assumed to happen when AI can readily automate sufficiently many tasks; my current best-guess value is 6% of tasks (weighted by 2020 economic value).
- AIs perform an increasing fraction of tasks in software and hardware R&D.
- The effects of AI automation on R&D interact multiplicatively with those from rising human investment. For example, if rising human investment doubles inputs to hardware R&D, and AI automation increases effective R&D inputs by 2X, then total hardware R&D inputs rise by 4X.
- After “wake up” the fraction of effective compute used for software and hardware R&D grows rapidly.
- $ on FLOP in the largest training runs.
- This increases due to a larger fraction of GDP spent on FLOP in the largest training run, and due to GDP growth.
- The fraction of global GDP spent on FLOP in the largest training run grows as discussed in the section that ignored AI automation: initially increasing ~3X per year while we increase the fraction of chips used for training, later doubling every ~3 years.
- AI automation increases GDP growth[45]Ignoring AI automation, GDP grows at ~3%/year due to exogenously growing labour and TFP. AI automation of goods and services increases GDP growth. I don’t model AI automation of generic R&D., which in turn increases g($ spend on FLOP in the largest training runs). For example if GDP growth increases from 3% to 7%, then g($ spend on the largest training run) increases by 4%.

A growing fraction of the world’s effective compute is used in the largest training run → AI can automate certain tasks for GDP and R&D → the world allocates growing fractions of capital, labour and effective compute to hardware R&D and software R&D tasks (the remainder is allocated to GDP) → GDP grows, hardware improves, software improves → we recalculate the stocks of capital, labour and (especially) effective compute.
In addition to this, the FTM models a number of other plausibly-important details.[46]A delay from hardware R&D to producing SOTA chips (sometimes you need to upgrade fabs or construct new ones); a distinction between the cumulative stock of AI chips and the annual production (I’ve talked about the latter); a “stepping on toes” parameter (so that 10 researchers make more … Continue reading
This playground lets you see trajectories of key quantities, enter your own inputs, and see the justifications for my preferred inputs – I recommend you give it a try! Those who want a deeper understanding of how the model works should read this mathematical description of the FTM (h/t Epoch for this).
Many thanks to Epoch for coding up and running the FTM.
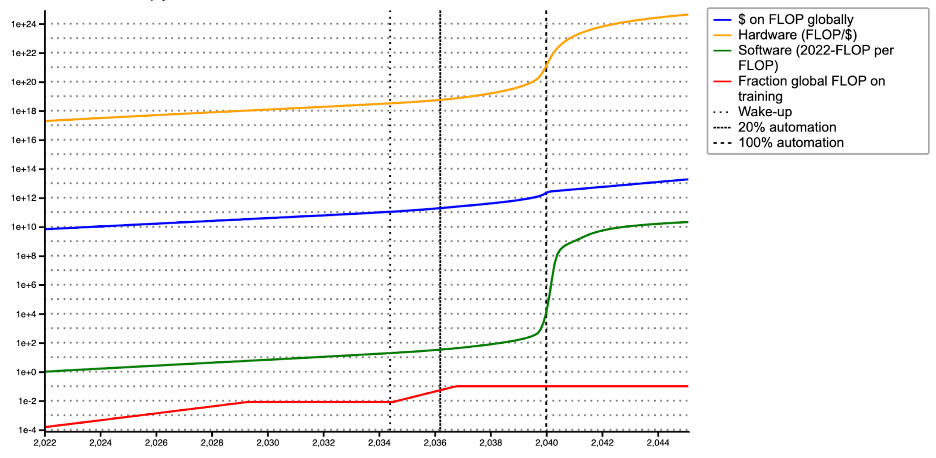
With my best-guess parameters, takeoff lasts ~5 years
I used my best-guess values for all parameters (discussed above and listed here): takeoff lasts ~5 years. The following graph show how the components of the largest training run evolve over time.
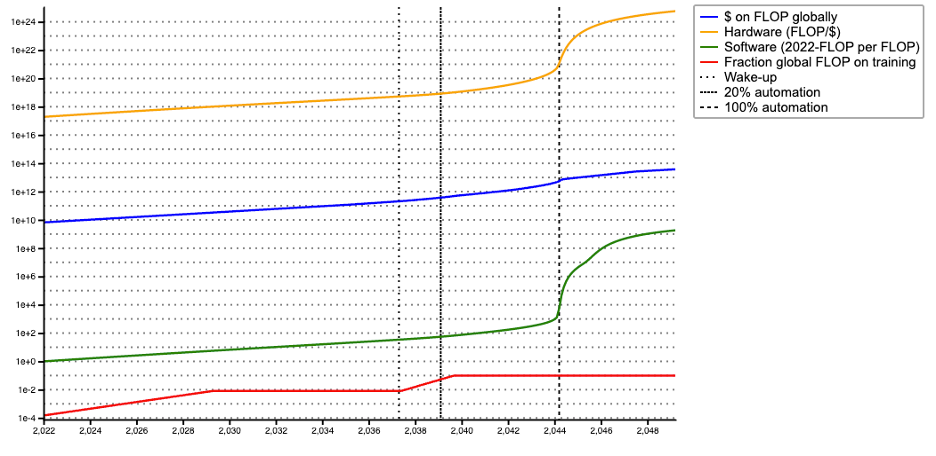
The report walks through the dynamics of this scenario and discusses other scenarios, where the parameters take conservative (slower takeoff) and aggressive (faster takeoff) values.[47]“Aggressive” parameter values sometimes shorten takeoff but lead to longer AI timelines. E.g. a small effective FLOP gap has this effect (see explanation below).
2.3 This model shortens AGI timelines, compared to Bio Anchors
The Full Takeoff Model (FTM) implies shorter AGI timelines than Bio Anchors. The most important reasons are:
- Speed-up from pre-AGI systems. Pre-AGI systems accelerate software and hardware progress; they also increase GDP and so increase the $ spent on FLOP globally.[48]Even if you don’t expect pre-AGI systems to significantly affect some sectors of GDP, it’s plausible that they significantly boost the number of AI chips produced and so of $ spent on FLOP globally.
- Effect size ~6 years
- Faster growth of % world GDP spent on a training run. Even ignoring AI automation, the FTM predicts that, a few years after “wake up”, we’ll use ~10% of global FLOP on the largest training run, with $ on FLOP globally continuing to double every ~3 years.
- Effect size ~2 years
The FTM also models factors that make timelines longer than Bio Anchors.
The following table compares the best-guess timelines implications of FTM with those of Bio Anchors.[49]The table compares the Bio Anchors forecast for “transformative AI” with the FTM’s forecast for “AI that could readily automate 100% of cognitive tasks”. The latter is a higher bar, so the shift in timelines is bigger than what the table suggests. The comparison assumes AGI (AI that could … Continue reading
| FLOP to train AGI using 2020 algorithms | Effective FLOP gap | Bio-anchors timelines
Year of TAI |
FTM timelines
Year AI could readily automate ~all cognitive labour |
Timelines shift |
| ~1e33 | 3 | 2043 | 2038 | 5 |
| ~1e36 | 4 | 2050 | 2044 | 6 |
| ~1e39 | 6 | 2062 | 2050 | 8 |
These timelines shifts are very sensitive to the size of the effective FLOP gap. Holding AGI training requirements fixed, a larger effective FLOP gap makes AGI sooner by lowering the training requirements for AI that significantly accelerates AI progress. More on this comparison.
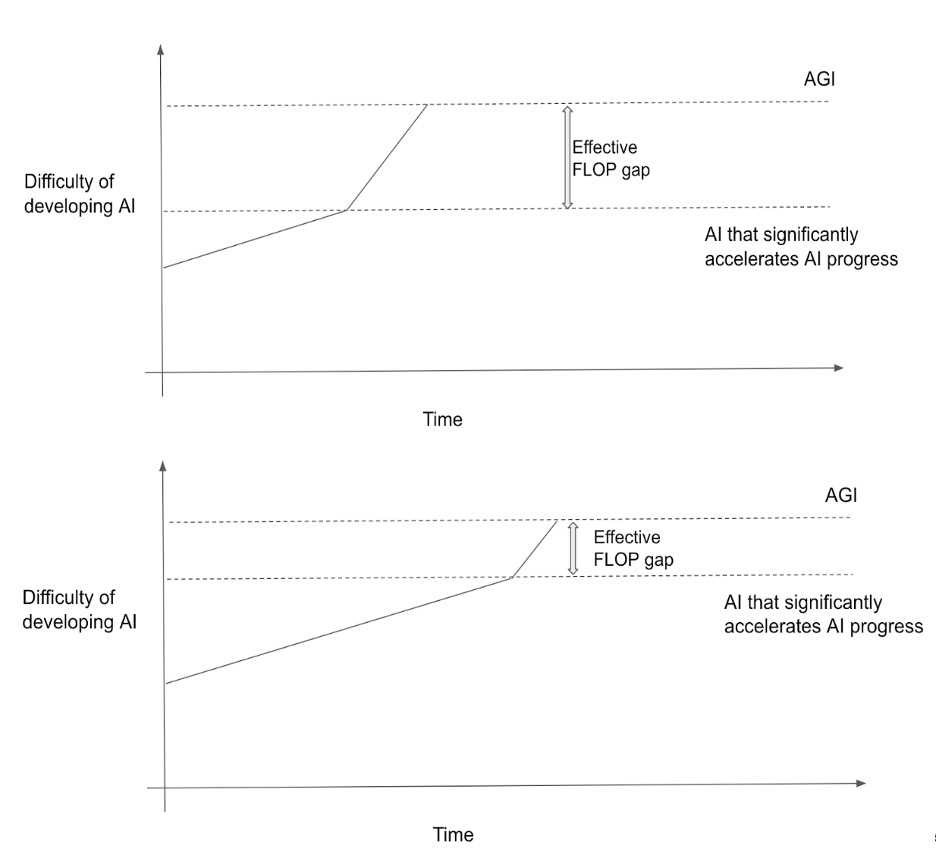
More qualitatively, this research has increased my probability that we’ll develop AGI by 2060. Even if the training requirements for AGI are really high, the requirements for “AI that adds $trillions to GDP” or “AI that notably accelerates hardware or software progress” might be significantly lower. Hitting either of these lower bars could spur further progress that soon gets us all the way to AGI. In the language of this report, I think that avoiding AGI by 2060 probably requires both large AGI training requirements and a narrow effective FLOP gap.[50]This is a bit oversimplified. Poor returns to hardware and software R&D could prevent us from hitting the lower thresholds in time, and hardware/software R&D progress will slow when the fraction of GDP spent on these areas stops increasing as it must do eventually. Another possibility is … Continue reading
2.3.1 Trading off training FLOP for runtime FLOP can shorten timelines
It is often possible to improve AI performance by allowing a model to “think” for longer (e.g. generating many answers, evaluating them, submitting the best); this often has the same effect as increasing training size by several OOMs.[51]See Jones (2021), AlphaCode, Codex, WebGPT. More.
For example OpenAI found that {generating 100 solutions and then evaluating which is best} improved performance at solving math problems as much as increasing model size by 30X.
This suggests we could achieve the same performance as an AGI by doing a smaller training run but allowing the AI to think for longer. E.g. perhaps our training run is 10X smaller than is required for AGI, but we make up for this by giving the trained model 100X the thinking time.
Indeed, my best-guess AGI training requirements (1e36 FLOP with 2020 algorithms) and runtime requirements (1e16 FLOP/s with 2020 algorithms), with some other assumptions, imply that we will be able to run ~10 trillion AGIs by the time we train AGI. In other words, there will be an abundance of runtime compute, especially relative to the 10,000s of people working on software R&D for SOTA AI. If we can leverage this abundance we might achieve the output of, say, 1 billion AGIs long before doing a 1e36 training run.[52]For example, suppose we do a 1e34 training run and then run the resultant 1e34-AI using enough compute to run 100 billion 1e36-AIs. Perhaps, because our training run is 100X below the AGI training requirement, we get the same output as if we’d run 1 billion 1e36-AIs. We’d be trading off 2 OOMs … Continue reading I think this could reduce the training run size needed for full automation by 1-3 OOMs, possibly more.
When this dynamic is included in the FTM, best guess timelines shorten by ~5 years.
2.4 Monte Carlo
We ran 10,000 simulations, each time randomly sampling each parameter between its “conservative” (slower takeoff) and “aggressive” (faster takeoff[53]Note, parameters that are “aggressive” for takeoff speed are sometimes “conservative” for AI timelines. In particular a narrow effective FLOP gap (holding AGI training requirements fixed) makes takeoff faster but delays AGI.) values (listed here).[54]The sampling distribution is a mixture of two distributions. It places 50% weight on a log-uniform distribution between the parameter’s “conservative” and “best-guess” value, and 50% weight on a log-uniform distribution between its “best-guess” and “aggressive” values. The only … Continue reading
We encoded correlations between the parameters. The most important correlations are:[55]These high-level correlations, and others, are recorded here; the full matrix of correlation is here. I think I’ve overestimated the correlations between these inputs, extremizing the tail outcomes. On the other hand, my sampling procedure means the parameter values never fall outside the … Continue reading
- Strong correlation between growth of AI investments across areas. If spending in one area of AI (e.g. software R&D) grows quickly, I also expect spending to grow quickly in other areas (e.g. hardware R&D).
- Medium correlation between AGI training requirements and the effective FLOP gap. If AGI requires “long horizon” training, or some other high-cost approach to training, that increases my probability that 20% of tasks will be automated with much less effective training compute than AGI.
- Medium correlation between AGI training requirements and growth of AI investments. If AGI training requirements are lower, it should be easier to grow AI investments quickly as they’re starting from a lower base.
We resample the parameters, except AGI training requirements[56]Bio Anchors already adjusted its training requirements distribution to account for the fact that we’re seemingly not close to training TAI today; resampling training requirements here would double-count this update., until we avoid the implication that AI can already readily automate >1% of the economy or >5% of R&D. This reduces the median sampled effective FLOP gap from 4 OOMs to 3.3 OOMs.
Here are the results, sampling AGI training requirements from the Bio Anchors best-guess distribution.[57]We assume AGI training requirements are 1 OOM higher than TAI training requirements, and reduce the probability of “you need more compute than evolution” from 10% to 4%.
| Percentile | First year when AI can readily automate 100% of cognitive tasks in the general economy. |
| 1% | 2025.7 |
| 10% | 2029.6 |
| 20% | 2032.7 |
| 50% | 2043.3 |
| 80% | 2070.3 |
| 90% | ≥ 2100 |
| 99% | ≥ 2100 |
| Percentile[58]This is all conditional on AGI before 2100. | Takeoff speed
Years from “AI can readily automate 20% of cognitive tasks” to “AI can readily automate 100% of cognitive tasks”. |
|
| Tasks in the general economy. | Tasks in software and hardware R&D. | |
| 1% | 0.3 | 0.9 |
| 10% | 0.8 | 1.6 |
| 20% | 1.2 | 2.2 |
| 50% | 2.9 | 4.3 |
| 80% | 7.6 | 9.6 |
| 90% | 12.5 | 14.6 |
| 99% | 28 | 30.7 |
Compared to my previous best-guess scenario where AGI training requirements are 1e36, the Monte Carlo’s median takeoff speed is faster (3 years vs 5 years). This is because:
- The median effective FLOP gap in the Monte Carlo is shorter than the best-guess (3.3 vs 4 OOMs)
- The Monte Carlo allows for the possibility that it’s easier for AI to automate cognitive tasks in {software and hardware R&D} than in the general economy, which speeds up takeoff in expectation.
2.4.1 Monte Carlo with aggressive training requirements
My median AGI training requirements (~1e36 FLOP using 2020 algorithms) are high compared to some. I reran the Monte Carlo on an alternative distribution with a more aggressive distribution that has a median of ~1e31.
| Percentile | First year when AI can readily automate 100% of cognitive tasks in the general economy. |
| 1% | 2024.8 |
| 10% | 2027 |
| 20% | 2028.6 |
| 50% | 2033.7 |
| 80% | 2044.1 |
| 90% | 2054.9 |
| 99% | ≥ 2100 |
| Percentile[59]This is all conditional on AGI before 2100. | Takeoff speed
Years from “AI can readily automate 20% of cognitive tasks” to “AI can readily automate 100% of cognitive tasks”. |
|
| Tasks in the general economy. | Tasks in software and hardware R&D. | |
| 1% | 0.2 | 1.1 |
| 10% | 0.5 | 1.7 |
| 20% | 0.7 | 2.2 |
| 50% | 1.7 | 3.7 |
| 80% | 3.9 | 6.4 |
| 90% | 6.1 | 9.1 |
| 99% | 20 | 24.2 |
Unsurprisingly, lowering median training requirements by 5 OOMs makes timelines significantly shorter and takeoff significantly faster.
2.4.2 Alternative ways to think about takeoff speeds
Reporting the time between two somewhat-arbitrary AI capability levels gives a limited view into the dynamics of takeoff. Another approach is to ask “What does the world look like Y years before AI can readily automate all cognitive tasks?”. Here’s one example (more):
| Doubling times (median[60]The median percentile for hardware will in general not be the same simulation run as the median percentile for software. And similarly for GWP and for other percentiles. The percentiles are calculated for each quantity separately.)
X years before AI can readily automate 100% of tasks |
||||
| Quantity | 1 year | 2 years | 5 years | 10 years |
| FLOP/$ | 0.3 | 1.2 | 2.7 | 3.1 |
| Software | 0.2 | 1.2 | 2.4 | 2.9 |
| GWP[61]The model doesn’t include lags to deploying AI, strongly suggesting that these GWP growth rates are too high. | 0.7 | 2.4 | 8.4 | 21.1 |
More about the Monte Carlo set-up; see full results.
2.5 Parameter-importance analysis
We analysed how much varying each parameter from its “conservative” to its “aggressive” value (listed here) affected the results, holding other parameters fixed. My conclusion is that the most important parameters for takeoff speed, in order, are:
- AGI training requirements.
- Effective FLOP gap.
- R&D parallelisation penalty (“If I double research efforts, how much faster is R&D progress?”)
- Software returns.
- How much easier is it for AI to automate the cognitive tasks in {software and hardware R&D} vs the general economy?
- A parameter describing how much unautomated cognitive tasks bottleneck R&D progress. It influences how much AI accelerates R&D progress when it’s automated some but not all cognitive tasks.
- How much can you reduce the training requirements for full automation by allowing AIs to think for longer? (I.e. the cap on the tradeoff between training and runtime compute.)
More on which parameters are important, and why.
2.6 The framework has many limitations
Here I briefly summarise key limitations of the framework, and how correcting for them would change predictions about timelines and takeoff speed.
- Assumes no lag between developing and deploying AI. More.
- → impacts of pre-AGI systems happen later → AGI happens later so slower takeoff
- But I don’t expect large lags for deployment in AI R&D and in chip production as these aren’t customer facing so face i) fewer regulations and ii) less back-lash from customers who distrust AI.
- → bigger lag for weaker AIs than for stronger AIs → faster takeoff
- I partly account for this by holding the necessary deployment lag fixed in the definition of the effective FLOP gap,[62]I define startpoint/endpoint of the effective FLOP gap as AI that can readily perform x% of tasks, where “readily” means that the necessary deployment lag is < 1 year. which narrows that gap.[63]In particular, holding the necessary deployment lag fixed strengthens the argument “practical barriers to partially automating tasks” and so pushes towards a smaller effective FLOP gap.
- But better AI may reduce the actual deployment lag down towards the necessary deployment lag.
- How these bullets net out depends on your exact definition of takeoff speed.[64]So far, I’ve focussed on the time for AI capabilities to go from some startpoint to some endpoint, without explicit reference to AI’s actual impact on the world. In this case, I expect takeoff to be slower than the model predictions due to the first sub-bullet. But if both the startpoint and … Continue reading
- → impacts of pre-AGI systems happen later → AGI happens later so slower takeoff
- Assumes AI capabilities improve continuously with additional inputs. More.
- If progress is in fact jumpy, then there could be a fast takeoff even with a wide effective FLOP gap.
- I find specific arguments for discontinuities unconvincing, but do assign it some probability.[65]I tentatively put ~6% on a substantial discontinuity in AI progress around the human range. (By “ substantial discontinuous jump” I mean “>10 years of progress at previous rates occurred on one occasion”.) More.
- If progress is in fact jumpy, then there could be a fast takeoff even with a wide effective FLOP gap.
- Assumes no lag in reallocating human talent when tasks have been automated.
- → fewer human workers than I assume improving AI → longer timelines
- This is important if pre-AGI systems fully automate certain jobs, less so if they partially automate jobs and workers continue to do the other parts.[66]E.g. Brynjolfsson (2018) finds that “most occupations include at least some [automatable by machine learning] tasks; (iii) few occupations are fully automatable using ML.”
- → fewer human workers than I assume improving AI → longer timelines
- Doesn’t model data/environment inputs to AI development. More.
- → takeoff could be slower if this input takes a long time to increase, or faster if it is quick to increase
- A more comprehensive framework might define a FLOP-data gap that can be crossed with more/better data/environments or with more compute.
- Some of the important dynamics I’ve analysed for compute (rising investment, AI automation) would apply to data as well, but others wouldn’t (the amount of high quality data isn’t already doubling every 1-3 years).
- → takeoff could be slower if this input takes a long time to increase, or faster if it is quick to increase
- Doesn’t model actors’ incentives to invest in training runs and AI R&D. Instead the model makes hacky assumptions about how investments change before and after the world “wakes up” to AI’s full economic and strategic potential. More.
More on limitations of the framework.
2.7 My all-things-considered probabilities
Adjusting for the above limitations, my overall probabilities change from the Monte Carlo as follows:
- About 10% more probability on <1 year takeoff.
- Mostly from a discontinuous jump in AI capabilities allowing it to cross even a large effective FLOP (/“difficulty gap”) very quickly.
- Expect somewhat slower takeoff in general (~30% longer).
- Lags to deploying AI in AI R&D and reallocating human labour.
- Unmodelled schlep to developing AIs (e.g. gathering data).
My all things considered views on takeoff speed differ from the Monte Carlo for a few of reasons, most importantly:
- Somewhat higher probability on <1 year takeoff, due to a discontinuity in AI progress causing us to cross a medium-sized gap very quickly.
- Longer takeoff speeds in general, due to the Full Takeoff Model ignoring various real-world frictions in developing and deploying AI.
- I’m not adjusting here for the possibility that we make an unusually large effort to slow down (e.g. delaying deployment by >6 months) due to caution about catastrophic risks from advanced AI. I’m just incorporating standard processes of testing and iterative deployment.
| Beliefs of the author
Percentile |
Takeoff speed
Years from “AI could readily automate 20% of cognitive tasks” to “AI could readily automate 100% of cognitive tasks”.[67]Reminder: Milestones of the form “AI could readily automate x% of tasks” require both that AI is capable enough to perform the tasks and that we can run enough copies for AI to replace every human doing those tasks. By contrast, the definition of AGI as “AI that could readily perform 100% of … Continue reading |
|
| Tasks in the general economy. | Tasks in software and hardware R&D. | |
| 3% | 0.1 | 0.3 |
| 10% | 0.3 | 1 |
| 20% | 0.8 | 2 |
| 50% | 3 | 5 |
| 80% | 10 | 12 |
| 90% | 20 | 25 |
2.7.1 Capabilities takeoff speed vs impact takeoff speed
Importantly, the above numbers, and my discussion more generally, has focussed on the takeoff speed of AI capabilities. To achieve the endpoint “AI could readily automate 100% of cognitive tasks” requires that AI is capable enough, and we have enough runtime compute, that AI could replace all human cognitive labour. It does not require that AI in fact has this impact.
How will AI’s impact takeoff speed differ from its capabilities takeoff speed? I think that:
- Deployment delays, e.g. due to human caution, will slow down impact takeoff speed. But competitive dynamics could limit these delays in certain strategically important fields.
- Once AI is significantly above human intelligence, it might remove these deployment delays, e.g. by disempowering humans or accelerating their deployment processes. This could mean that impact takeoff speed is faster than capabilities takeoff speed. More.
- Importantly, I expect the time from “AI actually adds $10tr/year to GDP” to “AI that could kill us if it wanted to” to be many years smaller than is predicted by the FTM, and plausibly negative, on account of deployment lags.
So overall I expect impact takeoff speed to be slower than capabilities takeoff, with the important exception that AI’s impact might mostly happen pretty suddenly after we have superhuman AI.
2.8 What about the time from AGI to superintelligence?
So far I’ve mostly focussed on the time from AI readily automating 20% of cognitive tasks to AI readily automating 100%.
But the time from AGI (AI that can readily perform 100% of tasks, without trading off training compute and runtime compute) to superintelligent AI is also strategically important. It tells us how much time we might have to adjust to somewhat superhuman AI before there is massively superintelligent AI.
The mainline prediction of this framework is that, unless we purposefully slow down, this time period will be extremely short: probably less than a year. The reasons are:
- Extremely fast software progress.
- Software for AI is already doubling roughly every year, from human efforts alone. By the time we train AGI we’ll be able to run enough AGIs to increase the cognitive labour used for software R&D by >10X. What’s more, these AGIs will be super-human in some areas, not require leisure time or sleep, and potentially think much faster than humans. This suggests the first software doubling after AGI will take 1 month or less.
- I argue that it’s more likely than not that there would be a ‘software-only singularity’ in this scenario, with software progress becoming faster and faster until total AI cognitive output has increased by several OOMs.
- You can see this effect in the playground with the green line representing software progress going “almost vertical” as we approach AGI.
- This isn’t guaranteed.
- Software progress may have become much harder by the time we reach AGI.
- Progress might become bottlenecked by the need to run expensive computational experiments, or to rerun multi-month long AI training runs.
- If AGI training requirements are very low (<1e28 FLOP) we may not be able to run enough AGIs to significantly accelerate R&D progress.
- But even with these barriers, I expect we could develop superintelligent AI within a year.
- Fast growth of physical compute.
- Years before we have AGI, we’ll have AI that can automate a significant fraction hardware R&D, speeding up the design of new AI chips. And we’ll have AI that can increase their throughput of fabs for manufacturing AI chips, or accelerate the construction of new fabs.
- This means that the quantity of physical compute in the world may be increasing very rapidly just as we first develop AGI.
- You can see this effect in the playground with the yellow line representing hardware progress “rising more steeply” as we approach AGI.
- Again, this is not guaranteed.
- Hardware progress may have become much harder by the time we reach AGI.
- Progress might be bottlenecked by the need to do physical experiments.
- It’s possible that deployment lags will be long enough that we have AGI before pre-AGI systems have had significant effects on hardware improvements.
2.9 Some high-level frames for thinking about the report’s conclusions
I agree with all of these; I’ve ordered them based on how useful I find them.
- If takeoff is fully continuous, it could be pretty fast. An important potential source of fast takeoff is that, while AI progress is continuous, the rate of improvement is still steep enough to drive fast takeoff.[68]This can be framed as a reply to Paul Christiano’s 2018 writing about takeoff speed: while he’s right that takeoff is probably continuous, it may yet be very fast. More.
- The ‘steep rate of improvement’ is driven by:
- Not-extremely-high AGI training requirements, implying a large increase in AI capabilities per OOM of additional training FLOP.
- Fast growth in the largest training run, driven by i) the fast growth of FLOP/$ and software, ii) room to significantly scale up $ spend on the largest training and incentive to do so, and iii) effects of AI automation.
- The ‘steep rate of improvement’ is driven by:
- No time for very slow takeoff unless AGI is very hard to develop. It’s hard to maintain the following three things:
- Pre-AGI systems will have huge impacts, e.g. generating $10s-100s trillions/year.
- The training requirements for AGI are not extremely large.
- There will be decades between pre-AGI systems with huge impacts and AGI.
These are hard to maintain because: (a) → very large increases in AI investments + significant speed-ups from AI automation → rapid increase in the largest training run. Then (b) + rapid increase in the largest training run → we train AGI within ~10 years → not-(c).
- IEM but with quantitative predictions. Intelligence Explosion Microeconomics (IEM) gave arguments for thinking AGI would lead to accelerating growth but didn’t (try to) ground things empirically or make quantitative predictions. The FTM does this via assumptions about future AI investments, the returns to hardware + software R&D, and the size of the effective FLOP gap. More.
- Quantifies the tradeoff between takeoff speed and timelines.
- Holding AGI training requirements fixed, a slower takeoff means AGI happens sooner (due to pre-AGI systems helping to develop AGI).
- The size of the effective FLOP gap controls this tradeoff. A wider gap makes takeoff slower but means AGI happens sooner.
- Augments growth models to make predictions about takeoff speed. More.
- Economic growth models have a strong tendency to predict that full automation of both goods production and R&D will cause large increases in both GDP and the GDP growth rate.[69]See section 8.2.
- According to these models, whether there is a “fast takeoff” in GDP depends on:
- How much time does it take to go from “most tasks can’t be automated” to “~all tasks can be”?
- Once all tasks are automated, how long does it take to amass enough (computer) capital that per-task output is much higher than it was when humans were doing the tasks?
- The FTM answers (i) by assuming that: the number of tasks you can automate is tied to the largest training run you’ve done; and the threshold for automating ~all tasks is based on Bio Anchors; and the threshold for lower levels of automation also depends on the effective FLOP gap.
- The FTM answers (ii) by modeling how the amount of compute and software change over time.
- Ultimately, the FTM finds it likely that i) we probably automate most cognitive tasks (weighted by economic importance in 2020) in a 5 year period and ii) very soon after this is done, total cognitive output from AI far outstrips that from humans.
2.10 Steel man case for fast takeoff
Given all of the above, here’s my strongest case for a fast takeoff:
- Small effective FLOP gap.
- Brain size – IQ correlations in humans are the only evidence we have of capability scaling in the human range, it suggests an effective FLOP gap of ~1 OOM.
- The practical difficulties of partial automation are significant, so significant partial automation will be possible only a little before full automation.
- Fast investment ramp up.
- The economic, military and strategic incentives to ramp-up investments in AI as we’re crossing the effective FLOP gap will be huge; the low current level of AI investments mean they could rise by 1-2 OOMs very quickly.
- Other important metrics of takeoff speed will be faster than the ones I’m reporting.
- Time from “AI that could provide clear alignment warning shots” is probably after “AI that could readily 20% of tasks”, and “AI that could kill us if it’s not aligned” is probably before “AI that could readily 100% of tasks”.
- The time when we actually see warning shots will be later than when we have AI that could provide those warning shots, making the situation even worse.
- Impact takeoff more generally could be faster than capabilities takeoff if superhuman AI quickly removes barriers to AI deployment. More.
- This point is very important.
- Another framework implies takeoff will be much faster.
- A different one-dimensional model of takeoff implies it will take ~0.5 – 2 years.
- However, this model ignores the fact that AI will probably surpass humans on some tasks long before others.
- AI capabilities might not improve smoothly with additional inputs.
- Discontinuities aren’t that rare; this raises the probability of fast takeoff above the results of the Monte Carlo.
2.11 Steel man case for slow takeoff
Here’s my strongest case for a slow takeoff:
- Large effective FLOP gap, high training requirements.
- “Short horizon” training will generate $trillions but won’t be enough to automate all cognitive tasks. That will take “long horizon training”, which will take >5 OOMs more FLOP.
- When you 300X training run size (as when going from GPT-2 to GPT-3) the performance increase isn’t that big, so we’ll need many such improvements to cross the effective FLOP gap.
- Rather than using training requirements to upper-bound the effective FLOP gap, we should use the effective FLOP gap to lower-bound training requirements.
- Slow ramp up of human investment in AI.
- Unmodelled bottlenecks will push towards slower takeoff.
- High quality data and environments; need for new algorithmic paradigms.
- I don’t model delays in deploying AIs and reallocating human workers.
- AI took decades to cross human range in many narrow domains.
- AI Impacts find this in chess, Go, and checkers.
- So we should be sceptical of any framework predicting we’ll cross the human range across most economically valuable tasks in <10 years.
- Some possible resolutions of this tension:
- The effective FLOP gap is on the high end of my estimates, implying high AGI training requirements.
- Progress in those games is slower because “ML progress is faster than GOFAI progress”,[70]This is suggested by figure 3 of this paper and by this graph. there was slower investment growth, and there weren’t speed-ups from AI automation of AI R&D.
- The range of “humans who get paid to play these games” gets crossed much more quickly than the full human range that includes amateurs; it’s the former range we’re interested in from the perspective of this report (which is about when AI could readily automate various fractions of the economy).
- The effective FLOP gap is narrower than in those games, e.g. because “capabilities scale especially quickly in the human range” or “it’s difficult to partially automate jobs”.
- This is a very important topic for further investigation.
3. Reading recommendations after the long summary
Here are the sections of the full report I think are most worthwhile reading after the long summary (in order).
- Evidence about the size of the effective FLOP gap – this is probably the most important and uncertain parameter for takeoff speed, perhaps after AGI training requirements.
- There’s a ~65% chance of a temporary “software-only singularity”, where AGIs improve software increasingly quickly while being run on a ~fixed hardware base.
- Takeoff speeds are faster according to a one-dimensional model of takeoff.
- A new version of the chimp-human-transition argument for very fast takeoff.
- Trading off training FLOP for runtime FLOP shortens timelines.
- A list of open questions.
Footnotes
| 1 | The phrase “readily” here indicates that i) it would be profitable for organisations to do the engineering and workflow adjustments necessary for AI to perform the task in practice, and ii) they could make these adjustments within 1 year if they made this one of their priorities. |
|---|---|
| 2 | Milestones of the form “AI could readily automate x% of tasks” require both that AI is capable enough to perform the tasks and that we can run enough copies for AI to replace every human doing those tasks. By contrast, the definition of AGI as “AI that could readily perform 100% of tasks” only requires that we could run one copy. |
| 3 | By contrast, in Superintelligence takeoff speed is defined as the time from human-level AI to superintelligence. I discuss this, but it is not my focus because I think the bigger crux in takeoff speeds relates to the time from sub-human but hugely impactful AI to human-level AI (more). |
| 4 | The explicit forecasting target of Bio Anchors is “transformative AI”, but the framework can be used to forecast AGI. |
| 5 | More precisely, if experts in 2020 were given ~2-5 years to experiment with the new quantity of compute and design a training run, they could train AGI (more). |
| 6 | This is a slight oversimplification. Takeoff time as defined here is time from AI that could readily perform 20% of tasks to AI that could perform 100%. Whereas the metric I ultimately report is AI could readily automate 20% to 100%. The latter accounts for whether we have enough compute to run enough copies to automate those tasks in practice, given the size of the human population. In practice though, this mostly makes very little difference to the results (<1 year) because runtime compute is rarely a bottleneck. |
| 7 | Why 20%? The choice of startpoint is fairly arbitrary. 5% would be too low, as it could be driven by a few one-off wins for AI like “automating driving”; 50% would be too high as by then AI may already be having ~transformative impact. |
| 8 | Conditional on 100% automation by 2100. |
| 9, 12 | Reminder: milestones of the form “AI could readily automate x% of tasks” require both that AI is capable enough to perform the tasks and that we can run enough copies for AI to replace every human doing those tasks. By contrast, the definition of AGI as “AI that could readily perform 100% of tasks” only requires that we could run one copy. |
| 10 | Why is takeoff slower for AI R&D tasks? The Monte Carlo puts weight on AI R&D being significantly easier to automate than the general economy. If so then, by the time AI can readily automate 20% of tasks in the general economy, it will have already automated most tasks in AI R&D and significantly accelerated AI progress. This factor speeds up takeoff for tasks in the general economy but not for tasks in R&D. |
| 11 | If AGI could be trained with X OOMs more effective compute than today’s largest training run, the effective FLOP gap must be <X OOMs. |
| 13 | This could be one generally capable AI, or many narrow AIs working together. I think the takeoff model I ultimately use sits better with the latter interpretation. |
| 14 | By “cognitive task” I mean “any part of the workflow that could in principle be done remotely or is done by the human brain”. So it includes ~all knowledge work but also many parts of jobs where you have to be physically present. E.g. for a plumber it would include “processing the visual and audio inputs relating to the problem, choosing a plan to solve it, and deciding what specific actions to take second by second”. But it doesn’t include the “pure physical labour” parts of plumbing that require a physical body. |
| 15 | First, it will be hard to measure in practice what % of cognitive tasks AI can perform (more). Second, there are not literally a fixed set of tasks in the economy; new tasks are introduced over time and AI will contribute to this (more, more). Thirdly, at what cost can AI perform these tasks? The model implies it will be able to perform them very cheaply, more cheaply than humans (more). Fourth, whether AI can perform a task may depend on whether ‘nearby’ tasks have already been automated, but I don’t model this (more). |
| 16 | E.g. here, here, here, here. I don’t know how reliable these estimates are, or even their methodologies. |
| 17 | AI’s impact on GDP may be greater than its market size, but it would have to have to be adding ~$0.5tr/year to GDP to have automated 1% of cognitive tasks. |
| 18 | Why 20%? The choice of startpoint is fairly arbitrary. 5% would be too low, as it could be driven by a few one-off wins for AI like “automating driving”; 50% would be too high as by then AI is already having ~transformative impacts. |
| 19 | World GDP is ~$100tr, about half of which is paid to human labour. If AI automates 20% of that work, that’s worth ~$10tr/year. [This is a bit high, as many tasks have a component of physical labour (though all have some cognitive component). On the other hand, AI will probably produce more output at those tasks than the humans they replace (as they’re cheaper to run), increasing their value-add; and AI will additionally increase the rates of capital accumulation and of tech progress.] |
| 20 | More precisely, deployed anywhere where i) it would be profitable for organisations to do the engineering and workflow adjustments necessary for AI to perform the task in practice and ii) they could make these adjustments within 1 year if they made this one of their priorities. |
| 21 | Reminder: if AI can “readily” perform a task then i) it would be profitable for organisations to do the engineering and workflow adjustments necessary for AI to perform the task in practice, and ii) they could make these adjustments within 1 year if they made this one of their priorities. |
| 22 | E.g. Brynjolfsson (2018) finds that “most occupations include at least some [automatable by machine learning] tasks; (iii) few occupations are fully automatable using ML; and (iv) realizing the potential of ML usually requires redesign of job task content. |
| 23 | This concept is from Bio Anchors. Short horizons means that the model only needs to “think” for a few seconds for each data point; long horizons means the model needs to “think” for months for each data point and so training requires much more compute. |
| 24 | There are ~5 OOMs between a “10 second” horizon length and a “1 month” horizon length. |
| 25 | This could be either AI organisations reinvesting revenues from AI products, or impressive demos attracting external investment. I don’t model either in detail and instead just try to ballpark the overall rate of investment growth. |
| 26 | This, like FLOP production as we approach AGI, is an example of “growth of a specific industry’s output when there is suddenly very large demand”. |
| 27 | This assumes the growth rates are instantaneous growth rates, defined as e^gt. All the growth rates I report are instantaneous. |
| 28 | This, like hardware R&D as we approach AGI, is an example of “growth of a specific industry’s R&D when there is suddenly very large demand”. |
| 29 | This sheet illustrates the dynamic. |
| 30 | The Full Takeoff Model caps total hardware R&D spending at 1% of global GDP. |
| 31 | The report operationalises “a doubling of software” to mean: your algorithms now use physical FLOP twice as efficiently. So doubling software has exactly the same effect as doubling your quantity of physical FLOP. |
| 32 | Time = distance / speed = 3 OOMs to cross without the fraction / [~0.4 OOMs/year] = ~8 years. |
| 33 | 1 OOM to cross with the fraction * 3 years per OOM = 3 years. |
| 34 | The resultant model of automation is perhaps most similar to Hanson (2000). |
| 35 | Automating a task requires both that AI can perform it and that there’s enough runtime compute to automate the task in practice (i.e. enough compute to cheaply replace the humans currently doing the task). It turns out that runtime compute is rarely a bottleneck to automation. |
| 36 | Here I’m assuming that AI output-per-task at least keeps up with human output per task. I can assume this because it’s a condition for AI automating the tasks in the first place. |
| 37 | If AI had automated x% of tasks, the boost here would equal 1/(1-x%). |
| 38 | In the growth model, the strength of this bottleneck depends on the substitutability between different tasks: how much can more AI labour on task 1 make up for limited human labour on task 2? |
| 39 | The Full Takeoff Model assumes that the percentage of global compute used to run AIs doing software rises quickly to a cap of ~20% after “wake up”. |
| 40 | Here’s the formula. If AI automates x% of tasks, the minimum effect is 1/(1-x%); the maximum effect is 1/(1-x%)^(1 + 1/-rho), where rho controls the strength of the bottleneck. My best guess is rho=-0.5, so the maximum effect is 1/(1-x%)^3. 1/(1-0.2) = 1.25, 1.25^3=1.95; 1/(1-0.75) = 4, 4^3=64. |
| 41 | I.e. an amount of effective compute equivalent to using 1e36 FLOP with 2020 algorithms. |
| 42 | This is the short term boost to annual R&D progress you’d get if you instantaneously automated 50% of R&D tasks. Longer term, your faster R&D progress would increase diminishing returns and so your rate of annual progress would slow over time. The short term boost calculation is roughly accurate if the effective FLOP gap is very narrow; if it’s wide then the calculation will overestimate the rate of R&D progress, perhaps significantly. This is accounted for in the FTM. |
| 43 | These results are strikingly similar to those of a simple toy model. In the toy model, crossing the effective FLOP gap corresponds to travelling along the x-axis from 1 to 0. Without AI automation your speed equals 1 unit/second throughout; you cross the entire effective FLOP gap in one second and the final fraction f of the gap in f seconds. With AI automation, your speed equals 1/x throughout, increasing over time; it turns out that you cross the entire effective FLOP gap in 0.5 seconds and the final fraction f of the gap in (f^2)/2 seconds. Time to cross final fraction f of the gap without automation / time to cross final fraction f of the gap with automation = f / [(f^2)/2] = 2/f. In our case, f = 0.8 and so the ratio is 2.5X, as found in simulation. |
| 44 | One caveat here: once GDP starts growing more quickly, physical capital starts growing more quickly too. This causes capital inputs to hardware R&D grow somewhat more quickly than 17%. |
| 45 | Ignoring AI automation, GDP grows at ~3%/year due to exogenously growing labour and TFP. AI automation of goods and services increases GDP growth. I don’t model AI automation of generic R&D. |
| 46 | A delay from hardware R&D to producing SOTA chips (sometimes you need to upgrade fabs or construct new ones); a distinction between the cumulative stock of AI chips and the annual production (I’ve talked about the latter); a “stepping on toes” parameter (so that 10 researchers make more progress in 10 years than 100 researchers make in 1 year); assumptions about training and runtime requirements for AI that can perform x% of cognitive tasks, for all x; AIs are heavily concentrated on doing AI R&D after “wake up”; AI advantages at R&D due to e.g. faster thinking speed; ceilings on FLOP/$ and software; returns to hardware and software R&D become worse as we approach their ceilings; ceilings on the fraction of world GDP spent on hardware R&D, on software R&D and on buying FLOP; and the assumption that “wake up” happens when AI has automated 3% of cognitive tasks (weighted by their economic value in 2020). |
| 47 | “Aggressive” parameter values sometimes shorten takeoff but lead to longer AI timelines. E.g. a small effective FLOP gap has this effect (see explanation below). |
| 48 | Even if you don’t expect pre-AGI systems to significantly affect some sectors of GDP, it’s plausible that they significantly boost the number of AI chips produced and so of $ spent on FLOP globally. |
| 49 | The table compares the Bio Anchors forecast for “transformative AI” with the FTM’s forecast for “AI that could readily automate 100% of cognitive tasks”. The latter is a higher bar, so the shift in timelines is bigger than what the table suggests. The comparison assumes AGI (AI that could readily perform 100% of cognitive tasks) requires 1 OOM more effective compute to train than transformative AI. |
| 50 | This is a bit oversimplified. Poor returns to hardware and software R&D could prevent us from hitting the lower thresholds in time, and hardware/software R&D progress will slow when the fraction of GDP spent on these areas stops increasing as it must do eventually. Another possibility is that AI has big economic impacts but isn’t useful for AI R&D. |
| 51 | See Jones (2021), AlphaCode, Codex, WebGPT. More. |
| 52 | For example, suppose we do a 1e34 training run and then run the resultant 1e34-AI using enough compute to run 100 billion 1e36-AIs. Perhaps, because our training run is 100X below the AGI training requirement, we get the same output as if we’d run 1 billion 1e36-AIs. We’d be trading off 2 OOMs of runtime compute for 2 OOMs of training compute. |
| 53 | Note, parameters that are “aggressive” for takeoff speed are sometimes “conservative” for AI timelines. In particular a narrow effective FLOP gap (holding AGI training requirements fixed) makes takeoff faster but delays AGI. |
| 54 | The sampling distribution is a mixture of two distributions. It places 50% weight on a log-uniform distribution between the parameter’s “conservative” and “best-guess” value, and 50% weight on a log-uniform distribution between its “best-guess” and “aggressive” values. The only exception is AGI training requirements, which are sampled from the Bio Anchors distribution. |
| 55 | These high-level correlations, and others, are recorded here; the full matrix of correlation is here. I think I’ve overestimated the correlations between these inputs, extremizing the tail outcomes. On the other hand, my sampling procedure means the parameter values never fall outside the “conservative” to “aggressive” range, which pushes in the opposite direction. |
| 56 | Bio Anchors already adjusted its training requirements distribution to account for the fact that we’re seemingly not close to training TAI today; resampling training requirements here would double-count this update. |
| 57 | We assume AGI training requirements are 1 OOM higher than TAI training requirements, and reduce the probability of “you need more compute than evolution” from 10% to 4%. |
| 58, 59 | This is all conditional on AGI before 2100. |
| 60 | The median percentile for hardware will in general not be the same simulation run as the median percentile for software. And similarly for GWP and for other percentiles. The percentiles are calculated for each quantity separately. |
| 61 | The model doesn’t include lags to deploying AI, strongly suggesting that these GWP growth rates are too high. |
| 62 | I define startpoint/endpoint of the effective FLOP gap as AI that can readily perform x% of tasks, where “readily” means that the necessary deployment lag is < 1 year. |
| 63 | In particular, holding the necessary deployment lag fixed strengthens the argument “practical barriers to partially automating tasks” and so pushes towards a smaller effective FLOP gap. |
| 64 | So far, I’ve focussed on the time for AI capabilities to go from some startpoint to some endpoint, without explicit reference to AI’s actual impact on the world. In this case, I expect takeoff to be slower than the model predictions due to the first sub-bullet. But if both the startpoint and endpoint do refer to actual impact (e.g. “GDP grows at 5%” to “GDP grows at 20%”) then the second sub-bullet might more-than makes up for the first. An interesting case is if the startpoint incorporates impact but the endpoint doesn’t (e.g. “AI adds $10tr/year” to “AI could kill us if it wanted to”). In this case I expect takeoff to be faster due to deployment lags only applying to the startpoint. |
| 65 | I tentatively put ~6% on a substantial discontinuity in AI progress around the human range. (By “ substantial discontinuous jump” I mean “>10 years of progress at previous rates occurred on one occasion”.) More. |
| 66 | E.g. Brynjolfsson (2018) finds that “most occupations include at least some [automatable by machine learning] tasks; (iii) few occupations are fully automatable using ML.” |
| 67 | Reminder: Milestones of the form “AI could readily automate x% of tasks” require both that AI is capable enough to perform the tasks and that we can run enough copies for AI to replace every human doing those tasks. By contrast, the definition of AGI as “AI that could readily perform 100% of tasks” only requires that we could run one copy. |
| 68 | This can be framed as a reply to Paul Christiano’s 2018 writing about takeoff speed: while he’s right that takeoff is probably continuous, it may yet be very fast. More. |
| 69 | See section 8.2. |
| 70 | This is suggested by figure 3 of this paper and by this graph. |